【AIとアート入門】前編:「コンピュータは創造的か」の問いに私たちはどう答えるか? レフィーク・アナドールから近年の研究事例まで(講師:久保田晃弘)【特集:AI時代のアート】

レフィーク・アナドール《Unsupervised》(ニューヨーク近代美術館、2022-23)の展示風景 © 2023 The Museum of Modern Art. Photo: Robert Gerhardt
SHARE



Tokyo Art Beatでは特集「AI時代のアート」をスタートする。2023年にはChatGPTの登場などで「生成AI」に大きな注目が集まり、アート界でもAIをどのように扱うか、それは人間の創造性にどんな影響を与えるのかといった実践や議論が広まっている。2024年となった今年、その可能性と展望に様々な角度から迫ろうというのが本特集の目指すところだ。
まずは入門編として、「AIとアート」概論を前後編でお届け。「AI、人工知能」と聞いて少々身構えてしまう入門者に向けて、メディア・アート領域を中心に創作活動の理論と実践を行う久保田晃弘(多摩美術大学 メディア芸術コース教授)がわかりやすく解説。前編では基本的な考え方や用語の使用から、注目のアーティスト、近年の研究事例までを概観する。【Tokyo Art Beat】
*後編はこちら

*特集「AI時代のアート」のほかの記事はこちら(随時更新)

レフィーク・アナドール作品に見る、人間とコンピュータ・システムとのあいだに生まれる新たな意識
──AI研究は50年代に遡ることができますが、2022年12月にChatGPTが登場したことで、大規模言語モデル(Large Language Model, LLM)を用いたAIが一般的にグッと身近になり、ビジネスシーンや社会インフラの面でも、大きなインパクトを与えるものになりました。すでにヴィジュアルに関しては、テキストから画像を生成するDALL-E2やMidjourneyが2022年にリリースされていて、イラストレーターやアーティストの仕事はAIに取って代わられることもあり得るのではないか、といった不安も広がっています。
TABでは「AIとアート」という特集を組むにあたって、現在の状況を概観するような記事を作りたいと思い、久保田さんにお話を聞かせていただくことにしました。まず、AIとアートに関して押さえておくべき代表的な事例や、そこから見えてくる可能性について、お聞かせいただけますでしょうか?
久保田:「AI(人工知能)」と一言で言っても様々なものが含まれますが、まずは最近よく話題に上がる、機械学習やディープラーニングに関わるものから、取り上げていきたいと思います。
機械学習技術を大規模に用いることで良く知られ、賛否両論様々な言説が交わされているアーティストの代表例が、レフィーク・アナドール(1985年トルコ・イスタンブール生まれ)です。とくにニューヨーク近代美術館(MoMA)のロビーに展示された、最新作の《Unsupervised》(2022)は、MoMAのコレクションから約14万点弱の画像データベースを機械学習し、その特徴が圧縮された潜在空間のなかをウォークスルーしていくことで、新たな画像を生成していくものです。
この作品について議論するとき、使用されている技術を何となく「AI」と呼んでしまいますが、AIという言葉の起源、つまり「コンピュータによる人間の知能の代行」あるいは「人間の知能の仕組みに関する計算論的研究」という概念だけでもとても広いので、作品毎に、使用されている技術を明示、共有して、AIに対する言説の解像度を上げていく必要があります。たとえばアナドールの《Unsupervised》でいえばディープラーニングを用いた「機械学習」、あるいはタイトルの通り「教師なし学習」でしょうか。ざっくりとAIと言うのではなく、データや技術の使われ方やその意味をひとつ一つ考えていくことが、大切だと思います。


《Unsupervised》について、ニューメディアの理論家・批評家・アーティストであるレフ・マノヴィッチがMoMAのブログにこんなことを書いています(*1)。《Unsupervised》の機械学習に用いたデータベースは、MoMAが所蔵している作品の画像なので、その中心は20世紀のモダニズムの芸術です。そこには抽象やキュビスムを始めとする、近現代の様々な作品が含まれています。そうした20世紀美術のメインストリームは、何か新しいものを生み出すために伝統と決別し──つまりそれまでに行われたことを否定、あるいは拒絶して、新たな可能性を探ることでした。それに対して、アナドールが行ったニューラルネットワークによる機械学習のトレーニングは、これまで「否定していくべき」だったものを、逆にすべて入力データとして受け入れて、そこから何か別のものを生成している。そうした機械学習の方法を、マノヴィッチは「『メタ』保守的なアーティスト」といいました。
そこでマノヴィッチが持ってきたメタファーが、アンドレイ・タルコフスキー監督の映画『惑星ソラリス』です。『惑星ソラリス』では、人間とは異なる知性体が、主人公ケルヴィンの記憶を探索し、その意味や文脈をまったく理解しないまま、例えば過去に自殺した妻を、物質的実体として生成します。マノヴィッチは最後に「《Unsupervised》もまた、MoMAの所蔵作品を制作したアーティストの思考や衝動から切り離された、非常に身近でありながら異質なものを生み出している。おそらくそれは、人間とコンピュータ・システムとのあいだに出現するであろう、新しい意識のかたちをいち早く垣間見たものである」と肯定的に述べています。


マノヴィッチは《Unsupervised》を、既存の美術史の文脈やメディアアートの歴史に連ねたり、重ね合わせるのではなく、それを「メタ」保守的な人工アーティストが生み出す異質な文化言語とみなして、その出力を人間はどのように読むべきか、という観点から論じています。これはひとつの例にすぎませんが、このようにAIがつくったものの意味や可能性、そしてそれを受け取る人間の認識の限界を議論することは、とても重要なことだと思います。
機械学習によるフォーマリズムの再考
──アナドールの作品は、美術館のコレクションというものに、これまでと違うかたちで出会うことを可能にするものですね。美術史という観点からも興味深いです。
久保田:機械学習がクリエイターだけではなく、美術史や美学の研究者にとっても非常に面白いツールになりえることを主張している本があります。それが、今年MIT Pressから出版された、アマンダ・ワシレウスキの『コンピュテーショナル・フォーマリズム(Computational Formalism)』(2023)です。デジタル人文学と美術史を専門とする著者によるこの本は、美術史研究における機械学習やコンピュータ・ビジョン技術の利用を、「コンピュテーショナル・フォーマリズム(計算形式主義)」と名付けて、機械学習が美術史におけるフォーマリズムをどのように復活させ、それがどんな役割を果たすのかを論じています。

この本のなかでも言われているように、画像データベースを機械学習することの拡がりによって、網膜主義が復権しています。それは言い換えれば作品の視覚的要素、つまり色や形といった「いまそこにあるもの」を重視する、フォーマリズムによる美術分析の手法と重なります。もちろん、データとしての画像を分析することと、人間が何かを見ることとは大きく違いますが、それでも画像の機械学習と網膜主義、フォーマリズムは深く関連しています。実際、機械学習による作品の特徴分析──先ほどのアナドールが行っていることや、2016年にディープラーニングでレンブラントの作品の特徴を分析し、その新作をつくった試み(*2)は、基本的にはすべてデータとしての絵画、つまり作品そのものではなく、そのデジタル複製物を機械学習の入力として用いています。アルゴリズムの中に、視覚的なイリュージョン、作品や作者を取り巻く歴史や文化、時代ごとの解釈や批評などは明示的には含まれてはおらず、それらは人間が画像の生成とは別に後付けするだけです。
制作だけでなく、その解釈や批評において「いまそこにないもの」も重要な意味を持ちますし、近年の現代アートの言説は形式よりも、それが指し示している社会的、政治的な状況側面が強くなっています。機械学習がやろうとしていることが、そうした現代の風潮に対する、ある種の反動やオルタナティブであるかどうかは議論のあるところです。けれども、社会的、政治的側面を一旦横に置いて、もう一度、純粋に視覚的な形式を分析する方法として、機械学習は使用できるのかどうか、あるいはそこに何らかの意味や可能性があるのかどうかを、この本では「コンピュテーショナル・フォーマリズム」、つまり計算による形式主義と名付けて議論しています。
過去のフォーマリズムは次第にその純粋性を失って、形式以外の様々な要素が入り混んできましたし、人間の先入観や既成概念によるバイアスや見落としもありました。ですから、大量のデータの機械学習アルゴリズムによる分析が、そこに暗黙のうちに含まれていた人間の規範や価値観を露わにしたり、網膜的情報に限ることから逆に見えてくるものがあるのではないか。美術作品をその複製データだけから分類、分析しようとするコンピュータ科学の方法には、ワシレウスキも強く批判の目を向けていますが、それは同時に今日の美術における西洋中心主義や、男性中心主義も浮き彫りにしてくれます。機械学習を批判することは、機械学習によって批判されることでもあります。機械学習による美術分析には、様々な欠点があるからこそ、その欠点を人間が指摘することで、逆に人間が作ったジャンルやカテゴリーや、画像や言語の限界、アーカイヴや美術館に内在するバイアスといった、人間の側の問題点が浮き彫りになり、データとアルゴリズムという非人間的な手続きを通じて、それらを見直すことへとつながっていきます。
そのうえでワシレウスキは、機械学習に対する批判や議論を交わすこと自体が、美術史家とコンピュータ科学者が、互いに学び合う絶好の機会になるのではないかと主張します。
AIによる画像生成技術の進展によって、現代のコンピュータ科学者たちが、急に美術史や美学について語り始めました。それはもちろん前述のように、作品ではなく画像、人間の視覚や鑑賞ではなくデータ分析、という限られた、あるいは偏った視点によるもので、美術側から見れば「ちょっと待て」という部分がたくさんありますが、そのこと自体を決して否定してはいけないと思います。理工学系と人文学系の諍いとして、90年代後半の「ソーカル事件」(*3)がありました。哲学者が科学的概念を濫用していると物理学者がポストモダン思想家を厳しく批判したものですが、こうした一方的批判だけでば、何も建設的なことは生まれません。AIと美術に関しても、人文学が理工系を一方的に批判するという「逆ソーカル事件」を起さないようにしなければなりません。
ワシレウスキはむしろ、コンピュータ科学者が美術史や美学に対する無知や誤用に陥らないように、美術に対する言説について、美術史家や美学者との会話を促す必要があると主張しています。どちらかが一方的に正しいということはなく、両者が共に自己や自分の基盤や方法に対して批判的になる必要があります。
前述のように機械学習によって、視覚的な形態を優先することによる美術史の再網膜化が起きてしまうわけですが、そこにイメージの分類だけでなく美術史的な積み重ねや、美学的洞察、さらに作品鑑賞における人間の身体的経験をどのように絡めていけるのかは、美術と技術の双方にとって、とても重要なテーマになり得ます。さらに大きな文脈で言うと、人工知能のベースにある科学的認識論、西洋近代的な考え方をどうすれば乗り越えていけるのか。人文学がつくり出した20世紀の大きな歴史が批判的に見直されつつあるなかで、技術の導入による西洋主義の復活を避けるような議論が必要です。もちろんその背後にあるのは、今日の巨大IT企業や国家による、思考や生活のアルゴリズムによる操作や、解決主義のレトリックで、それはジャンルを超えた共通の問題です。
科学技術は問題の定義とその解決に取り組みますが、人文学は物事をいかに解釈できるか、いかに批評できるかを考えます。問題発見とその解決という、生産性や効率と結びつきやすい価値観とは距離を置きます。いまのAI技術、機械学習技術を、何かしらの問題の技術的解決ではなく、批評と解釈、あるいは考古学や人類学のような継続的視点で議論することで、実り豊かな対話の場が生まれるかもしれません。自動車ではなく、交通渋滞についての議論が必要なのです。美術史家であれば、今日のバイアスのかかった大きな歴史を見直したり、複数化するための技術や方法を考えることかもしれないし、技術者であれば、自分たちが作るものに含まれている、文化的な意味合いや歴史的文脈との結びつきを考えることかもしれません。もちろんそれはあまりにも楽天的な考え方で、どうやっても結局は喧嘩別れに終わってしまう、という意見もあるとは思いますが、たとえそうであったとしても、機械学習やAI技術によって、美術史家や美学者と、コンピュータ科学者が新たな対話を始める機会が生まれる方が良いと思っています。
「コンピュータは創造的か」という問いは適切ではない
──美術史家と科学者が相互の知を持ち合うような対話をすべき、というのは非常に重要な指摘ですね。そうしたことは実際にすでに起きているのでしょうか?
久保田:研究者、批評家でアーティストでもある英ゴールドスミス・カレッジのジョアンナ・ジリンスカが、2020年に『AI ART』という本を書きました。彼女自身が、人工知能をテーマにした2017年のアルスエレクトロニカのシンポジウムに招待されたことが、ひとつのきっかけとなって生まれた本ですが、この本は、人工知能を現代の美術や人文学の文脈に乗せて批評を行った、貴重な事例のひとつです。今日の画像生成や大規模言語モデル旋風が起こる前の、GoogleのDeep Dreamや、GAN(敵対的生成ネットワーク)の時代の言説ですが、アートとAIをめぐる、いくつかの重要な視点を提示しています。

この本が最初に指摘しているのが「『コンピュータは創造的になれるのか(Can computers be creative?)』という良くある問いは、AIを語るためには適切ではない」ということです。人工知能を使ったアートについて考えるときに、よく「コンピュータも創造的になれる」とか「人間ほどの創造性はない」という二項対立的な議論を行いがちですが、それは議論を誤った方向へと導きます。コンピュータを使った作品制作は、人工知能研究の始まりと同じく1950〜60年代に始まりましたが、その時代のコンピュータ・アートと、最近のAI駆動型のアートとの間には、そもそも存在論的な違いがあるのか、それともたんなる程度の違いに過ぎないのか。ジリンスカは、AIによるアートの生産よりもむしろ、アートの受容の問題を取り上げます。そしてアートを含む様々な人間の活動は、そもそもつねに技術的であり、ある程度は「アーティフィシャリー・インテリジェント(人工的に知的)」であったことを強調します。
ジリンスカは『AI ART』の前に『ノンヒューマン・フォトグラフィ(
Nonhuman Photography)』(2017)という本を書いています。写真はいかにして表象主義を超えられるのか、という問いを「写真はつねにある程度非人間的である」というテーゼから語り、さらにそれを人新世やポストヒューマンの問題と絡めていきます。彼女はこの議論を、AIに対しても連続的に拡張していくことができると考えています。AIや機械学習の問題は、人間の創造性というよりも、人新世を生み出した地球温暖化や環境問題、あるいはポストヒューマンの問題と地続きであるという視点なんです。

ジリンスカは「AI ART」は類型的な呼称ではなくひとつの命題であり、その「最大の野望は、『アート』と『人工知能』という2つの概念の概念的・学問的な出会いを演出することである」であると語っています。美術には美術の、AIにはAIの「厄介な歴史と価値」があります。その両者が出会う場をいかにつくっていけるのか。それはワシレウスキと共通の射程です。ジリンスカも言うように、AIの出現によって芸術制作の⽬的は変わるのか、AIは芸術の新しい条件や新しい観客を⽣み出すのか、そして芸術とはそもそも何なのか、AI後の芸術とその受け手は誰になるのか、といった継続的な問いをもう一度考えていく必要があります。そうすることで芸術家は、AIについてのよりよい物語を語ったり、AIとともに⽣きる、よりよい⽅法を想像できるようになるはずです。
歴史の連続性からAIをとらえ直す
久保田:ジリンスカは、こうしたある種の根源的な問いに関連して、AIとかかわる(非)写真プロジェクトを通じて、⾃動化された創造性と労働⼒の問題に関する議論を進めます。彼女は2018年に、Amazonが提供している「アマゾン・メカニカルターク(Amazon Mechanical Turk)」というサービスを利用した写真作品を制作しました。このサービスは、コンピュータと人間の作業を組み合わせることで、コンピュータだけでは不可能な仕事を行うクラウドソーシングサービスです。メカニカルタークというのは18世紀のチェスを指す機械人形でしたが、じつは自動機械ではなく、内部にチェスの達人が入って操っていたという、いってみればフェイクAIでした。

ジリンスカはこのチェス機械の名に由来するアマゾン・メカニカルタークを用いて、あたかも人間がAIにオーダーするように、100人の匿名のメカニカルターク、つまり世界のどこかにいるアノニマスな人々に写真を撮るよう依頼しました。その依頼は「自分がいる部屋の窓から景色を1枚だけ撮影する。その部屋に窓がない場合、次に開いている窓のある部屋に行って写真を撮る」という単純なものですが、参加者はそれに加えて、自分の考えに基づいて写真を美しく見せることを求められました。そして撮影された写真を集めて「View from The Window」という写真集をつくったのです。
この写真集は一見地味に見えますが、そこには人間と機械の創造性を研究するという目的だけでなく、社会学的な、そして地政学的な状況や意味が内包されています。数は100人と少ないものの、参加してくれた人は、世界中の労働力の人口統計学的なスナップショットになっています。同時にこの依頼には、写真史における神話的な出発点、つまり《ル・グラの窓からの眺め》(ニセフォール・ニエプス)という人間の目では決して見ることのできない、非人間的な写真への回帰も込められています。
AIの歴史において、とくに今日の画像生成において欠かせない、画像とテキスト(ラベル)を結びつけたデータベース(ImageNet)を作成するためには、アマゾン・メカニカルタークの労働力が不可欠でした。そしていま、AIもまたメカニカルターク同様に、人間の新たな労働力としてとらえられています。労働者は命令に従順でなければなりません。だからAIが賢くなることが、ある種の反逆のようにとらえられるのだと思います。
そしていま、私たちがOpenAIやGoogleなどが提供するAIを使ってしまうことで、今度は私たち自身がいつの間にか、巨大IT企業のメカニカルタークになっています。多くの人が、そうしたAIそのものが内在する経済性や政治性に気がつき始めています。「Nightshade」のような、制作物をAIに学習されないようにするツールも開発されています。著作権だけでなく、創造性と生産性や労働力の関係は、AIとアートの問題を考えていくときに、個人が決して忘れてはいけないことのひとつです。
──ジリンスカの「アーティフィシャリー・インテリジェント」という考え方は重要ですね。2023年は「AIによって人間の仕事が奪われるのではないか」といった焦りや不安がやたらと煽られる場面を目にしましたし、イラストレーター、写真家、アーティストといった人たちにも「他人事ではないぞ」という雰囲気があったと思います。しかしそうした大雑把な議論や不安に流されないためにも、その都度AIの要素を吟味し、ひとつの技術として歴史的、大局的に位置付けることで冷静になれそうです。
久保田:はい。ほかにもスイスのHEAD(ジュネーブ造形芸術大学)では「アーティフィシャル・デザイン(Artificial Design)」というプロジェクトが進められています。画像生成にせよ、テキストチャットにせよ、今日のAIは既存のデータを模倣、編集しているだけなので、結果は極めてプロトタイプ的、均質的なのですが、それにもかかわらず、機械学習による人間の代替に関して、極論とも言える偏ったメディア議論が巻き起こっています。AIは20世紀のチューリング・テストやサイバネティクスの文脈から生まれ、成長した流れのひとつなので、このプロジェクトでは、そのルーツである認知行動主義的なアプローチや、機械学習特有の心理学の理論を援用することで、機械との新しい協働の形を切り開こうとしています。
これらのプロジェクトに共通しているのは、AIを連続的にとらえるやり方です。起業家やビジネスマンは往々にして「いままでにない」「革新的」などと言いたがりますが、そうした切断はAIの本質を見失わせます。ジリンスカも、AIはコンピュータ・アートの程度の違いとして見ていますし、サイバネティクスはいまでは生活のあらゆる部分で活用されています。芸術におけるフォーマリズムも、20世紀の半ばから、賛否両論、紆余曲折がありましたが、それでも継続的に議論されてきました。そうしたものごとに対する連続的な見方が、いまこそ必要なのだと思います。
AIがもたらすのは「新たな鑑賞のパラダイム」
──現在のAIをめぐる状況を面白く感じました。これまで人文学は科学に一方的に憧れていて、逆に科学領域にとっては人文学の知は取るに足りないものだというイメージを持っていましたが、両者が手を組むことを考えるとわくわくします。
久保田:現在のAI技術でも、とりあえずはアナドールの《Unsupervised》のように、様々な画像を生成することはできるのですが、僕はこうした生成よりもむしろ鑑賞のパラダイムが機械学習によってどう変化するのかを考えることが必要だと思っています。
鑑賞というのは、これまで「何度も繰り返し見る」「じっくり見る」という、人間的、身体的なトレーニングに根ざしていました。しかし通信やデータベースの容量が飛躍的に増大したいまの時代に、いかにして世界を見るかが、様々な分野で深刻な問題になりました。『遠読:〈世界文学システム〉への挑戦』(フランコ・モレッティ著、2013)という本がありますが、この中に収められた「世界文学への試論」では、コンピュータ解析や進化論を援用し、翻訳を許容することで「いかにすべての本を読まずに世界文学を語るか」が論じられています。「精読」に相当する伝統的な美術鑑賞だけなく、「遠読」に相当する別の鑑賞パラダイムについても、同時に考えていかなければなりません。もちろん両者の共存と使い分けがポイントになるわけですが。
大きくてわかりやすい歴史というのは、ある種の情報圧縮の手法です。そのわかりやすさが危険なのです。わかりやすさは、細部や小さいものを隠蔽します。しかし、細部に拘泥しすぎると、それは従来のような蛸壺化や専門分野の細断化を招きます。細部を見たり、分散的に考えながら、領域を横断したり、複合していくためにはどうすればいいのか。世界に対する新たな見方、鑑賞方法が必要とされています。

ディープラーニングや機械学習によって、個々の作品をひとつずつ精読するという、これまでの人間の深い鑑賞の仕方を見直すことができるかもしれません。たとえばアナドールがMoMAの膨大なデータベースから生成した画像や映像も、マノヴィッチのように見知らぬものというよりも、多数の個体の連続的インデックスとみなしたほうが良いと思います。そうすることで、連続的に変化する視覚的フォームから、学習データに潜在していた暗黙の類似性を発見したり、人間の物語では無視されてきた、思わぬつながりを発見できるかもしれません。
アナドールが行ったことは、生成というよりもむしろ鑑賞行為とみなすべきだと思います。デュシャンは「作品と鑑賞者の対話」こそが芸術行為であるといいましたが、膨大なデータベースを機械学習によって圧縮した潜在空間の中をナビゲートしていくということは、潜在空間の中で作品と対話することだといえます。《Unsupervised》が示しているのは、MoMAのアーカイヴという世界に対する「遠読」の手法のひとつであり、そこで世界文学ならぬ世界芸術が見えてくるのかどうかを問うべきなのかもしれません。
僕自身は、汎用のAI技術を用いて作品制作を行ったり、エンターテインメント的なスペクタクルをつくりだすよりも、分析や批評のためのプラットフォームとして活用することに興味があります。音楽のキュレーターとしてのDJのように、キュレーターとAIが協働するとどのような展覧会が生まれるのか。もちろんそこには、前述の網膜主義的な限界が立ちはだかってはいるわけですが、それを乗り越えるのが、身体を持つ人間と、巨大な計算能力を持つ機械のハイブリッドなのだと思います。
──そのためには鑑賞者側がもっとデータベースの手綱を握ることが大事ですね。
久保田:そうです。ディープラーニングや機械学習の方法というよりも、それが用いたトレーニングデータにより着目していく必要があると思います。今日の画像生成AIや、チャットシステムがどのようなデータを学習しているのかを、つねに頭に入れておかなくてはいけません。
たとえば、画像生成AIのStable DiffusionやDALL・E 2で使われているのは、LAIONというクリエイティブ・コモンズで提供されている研究用の画像データベースです。LAIONはネット上から無作為に収集された画像リンクとそのメタデータからなるデータベースで、なかでも最大のLAION 5Bには、約58億5000万枚の画像が登録されています。そのメタデータには、OpenAIのCLIPというツールを用いてつけられたキャプションが含まれていて、このタグによって画像とテキストを結びつけています。
さらにLAION 5Bのメタデータには、同じくCLIPモデルによって評価された10段階の美的パラメータ(Aesthetic Weight)が含まれていて、その値が7以上のものだけを選んだ、LAION-Aestheticsというサブセットがあります。しかしながらこれが曲者で、「犬」という条件で Aesthetic Weight が9(最高値)の画像と0(最低値)の画像を比較しても、「なるほど」ではなく「うーむ」という感覚しか生まれません。Stable DiffusionはこのLAION-Aestheticsを用いて学習しているので、結果としてその出力は何だか似通った、美的に均質なものになりがちです。
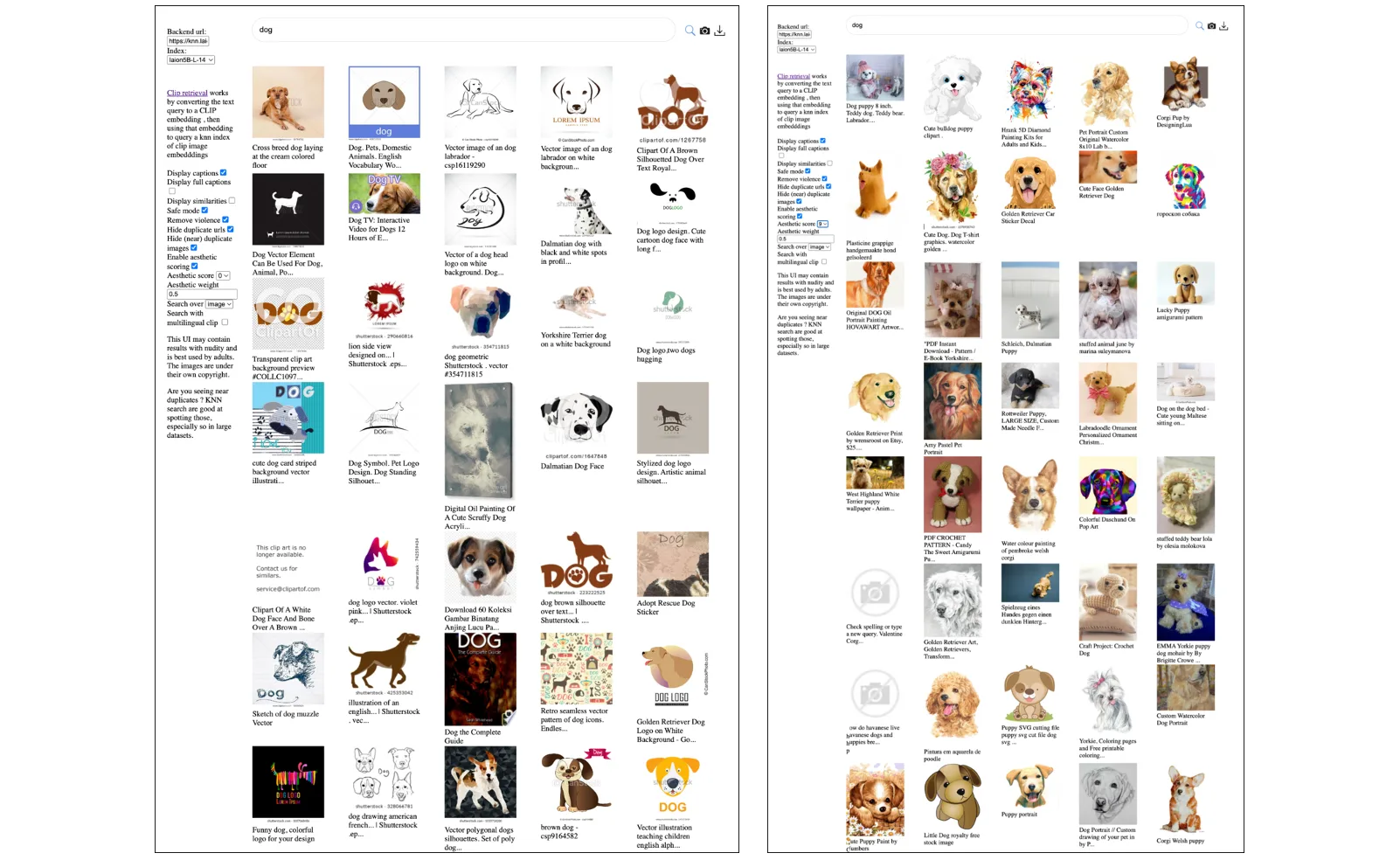
インターネット上の画像だけからなるデータベースには、西洋的価値や科学的価値のようなバイアスがかかっていて、世界の様々な文化やマイノリティーを平たく含むものではありません。当たり前のことですが、そもそもネット上にない画像は含まれていないわけですから、どんなに画像の枚数が多かったとしても、その文化的、歴史的な多様性は、極めて限られています。こうした技術やデータが持つ偏りや画一性、あるいはそれを生み出した経済構造や権力構造が、今日のAI技術を生み出しています。現在のAIは、人間同様に、多くの偏見に満ちていることから出発しないといけません。Google Mapsの道案内ではないですが、人はなぜか人間よりも機械のいうことを信じてしまいます。それがAIが持っている、いちばんの危険なのかもしれません。
*1──Lev Manovich「The AI Brain in the Cultural Archive」Jul 21, 2023 https://www.moma.org/magazine/articles/927
*2──人工知能などの最先端技術を駆使して17正規の画家レンブラントの“新作”を創るという試み。オランダのマウリッツハイス美術館とレンブラントハイス美術館のチームが、デルフト工科大学、マイクロソフトと協力して制作。346点に及ぶレンブラントの全作品が3Dスキャンを使ってデジタル化され、美術専門家の協力を得ながら、ディープラーニングアルゴリズムによって作品の特徴が分析。でき上がったイメージは、油絵具を用いて3Dプリントされた。オランダを本拠とする総合金融機関INGグループが出資している。
*3──ソーカル事件とは、1995年、ニューヨーク大学物理学教授のアラン・ソーカルが現代思想系の学術誌に論文を掲載したことに端を発する事件。論文はポストモダン思想家の文体をまねて科学用語や数式をちりばめた無内容なものであったが、それがそのまま受理・掲載されてしまった。ソーカルは論文のでたらめさを見抜けなかった専門家らを指弾するとともに、一部のポストモダン思想家が厳密な科学的意味に基づかないたんなる比喩や権威づけとして数学・科学用語を使用しており、こうした思想家らの著作がでたらめであると主張した。
【後編はこちら】

久保田晃弘
久保田晃弘
SHARE